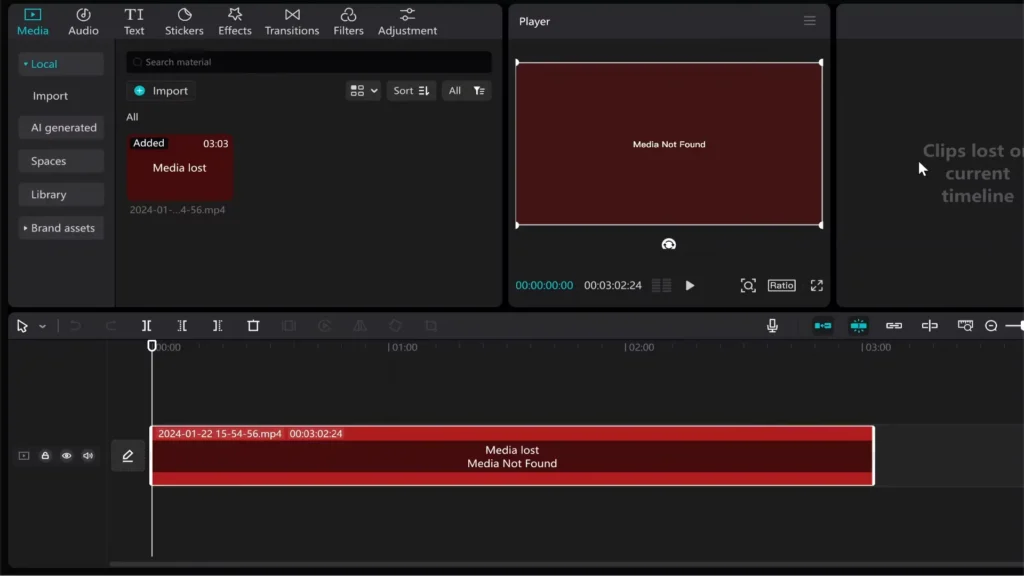
CapCut is one of the most popular free video editors available today, but for developers looking to automate or manipulate CapCut projects, there’s a frustrating limitation: even when the file paths in draft_info.json look correct, CapCut still asks you to manually re-link missing media.
In this guide, we’ll walk through why this happens, how CapCut projects are structured, and how to build a Python tool that automatically relinks lost media inside your CapCut drafts.
Understanding CapCut’s project structure
CapCut stores each project in a dedicated folder under:
CapCut/User Data/Projects/com.lveditor.draft/[project_id]/Inside this folder, you’ll typically find:
draft_info.json— Project metadata including media file paths and typesdraft_content.json— Timeline structure, edits, effects, transitionsmaterial/import/— Folder where media files are usually copied during importmedia/,fonts/,music/— Additional resources for the draft
CapCut references media via material_id and paths inside both JSON files. If anything doesn’t match CapCut’s expectations, it will ask the user to manually re-link the files.
Why CapCut still asks to Re-Link media
Even if you provide valid paths like this:
{
"path": "C:/Users/User/Videos/clip1.mp4",
"type": "video"
}CapCut may still show the media as missing. Here’s why:
- It checks for a valid
material_idlinked to the file - It likely validates the file hash or UUID based on file contents
- It uses an
import_timeor timestamp to match file metadata - Media may need to exist in a local folder like
material/import/
Auto-Linking with Python
To solve this issue, we can build a Python script that:
- Reads both
draft_info.jsonanddraft_content.json - Scans and updates media paths
- Regenerates
material_idvalues based on the file content - Sets updated import times
Python Script: capcut_media_relink.py
import os
import uuid
import json
import hashlib
def generate_uuid(file_path):
try:
with open(file_path, 'rb') as f:
content = f.read()
return str(uuid.uuid5(uuid.NAMESPACE_URL, hashlib.md5(content).hexdigest()))
except FileNotFoundError:
return str(uuid.uuid4())
def update_material_paths(project_folder, media_folder):
draft_info_path = os.path.join(project_folder, 'draft_info.json')
draft_content_path = os.path.join(project_folder, 'draft_content.json')
with open(draft_info_path, 'r', encoding='utf-8') as f:
draft_info = json.load(f)
with open(draft_content_path, 'r', encoding='utf-8') as f:
draft_content = json.load(f)
for mat in draft_info.get('materials', []):
filename = os.path.basename(mat.get('path', ''))
new_path = os.path.abspath(os.path.join(media_folder, filename))
mat['path'] = new_path
mat['material_id'] = generate_uuid(new_path)
mat['import_time'] = int(os.path.getmtime(new_path)) if os.path.exists(new_path) else 0
def update_ids(obj):
if isinstance(obj, dict):
for key, value in obj.items():
if key == 'material_id' and isinstance(value, str):
filename = value.split('/')[-1]
new_path = os.path.join(media_folder, filename)
obj[key] = generate_uuid(new_path)
else:
update_ids(value)
elif isinstance(obj, list):
for item in obj:
update_ids(item)
update_ids(draft_content)
with open(draft_info_path, 'w', encoding='utf-8') as f:
json.dump(draft_info, f, indent=2, ensure_ascii=False)
with open(draft_content_path, 'w', encoding='utf-8') as f:
json.dump(draft_content, f, indent=2, ensure_ascii=False)
print("Paths and UUIDs updated successfully.")
# --- CONFIG ---
project_folder = "C:/Users/YourName/CapCut/User Data/Projects/com.lveditor.draft/your_project_id"
media_folder = os.path.join(project_folder, "material", "import")
update_material_paths(project_folder, media_folder)Folder structure example
Before running the script, your project folder should look like this:
your_project_id/
├── draft_info.json
├── draft_content.json
└── material/
└── import/
├── clip1.mp4
└── music1.mp3The script will update both JSON files with valid paths and UUIDs that match the media content.
Common problems and fixes
Problem: CapCut still shows “Media Missing”
- Fix: Ensure the file actually exists in
material/import/and UUID is regenerated
Problem: Video loads but shows a black screen
- Fix: Use
FFmpegto re-encode media:ffmpeg -i input.mp4 -c:v libx264 -crf 18 -c:a aac output.mp4
Problem: CapCut crashes or won’t open draft
- Fix: Validate your JSON structure and compare with a working project
Developer use cases
Why would a developer want to inject media into CapCut?
- Export AI-generated video timelines into CapCut for editing
- Create reusable project templates for social media workflows
- Bridge between another NLE and CapCut (e.g., DaVinci Resolve -> CapCut)
- Auto-assemble CapCut drafts using server-side automation or scripts
CapCut version compatibility
CapCut may change its JSON schema or validation logic across versions.
Be sure to:
- Test your generated draft with a known CapCut version
- Check for required keys like
material_id,import_time,duration, etc. - Watch for new folder structure requirements in future updates
Legal & Ethical note
Reverse-engineering CapCut projects is for personal or automation use only. Don’t use this technique to modify commercial templates or violate any license agreements. This guide is intended to help developers integrate with their own CapCut workflows.
Resources
What’s next?
In future updates to this script, we plan to:
- Auto-create a draft project from scratch
- Support batch media injection
- Add a validation CLI to test CapCut draft compatibility
Have feedback or want to contribute? Leave a comment or fork the script on GitHub.



